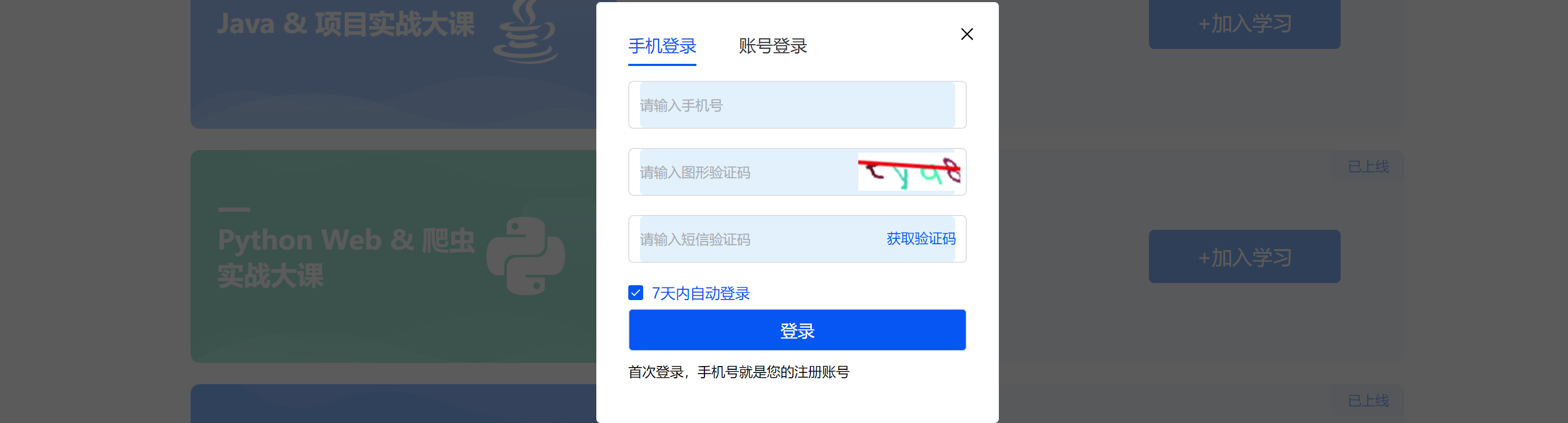
本节目标:图片验证码识别 + 其他
1.图片验证码
在很多登录、注册、频繁操作等行为时,一般都会加入验证码的功能。
如果想要基于代码实现某些功能,就必须实现:自动识别验证码,然后再做其他功能。


2.识别
基于Python的模块 ddddocr 可以实现对图片验证码的识别。
1
2
| pip3.11 install ddddocr==1.4.9 -i https://mirrors.aliyun.com/pypi/simple/
pip3.11 install Pillow==9.5.0
|
1
2
| pip install ddddocr==1.4.9 -i https://mirrors.aliyun.com/pypi/simple/
pip install Pillow==9.5.0
|
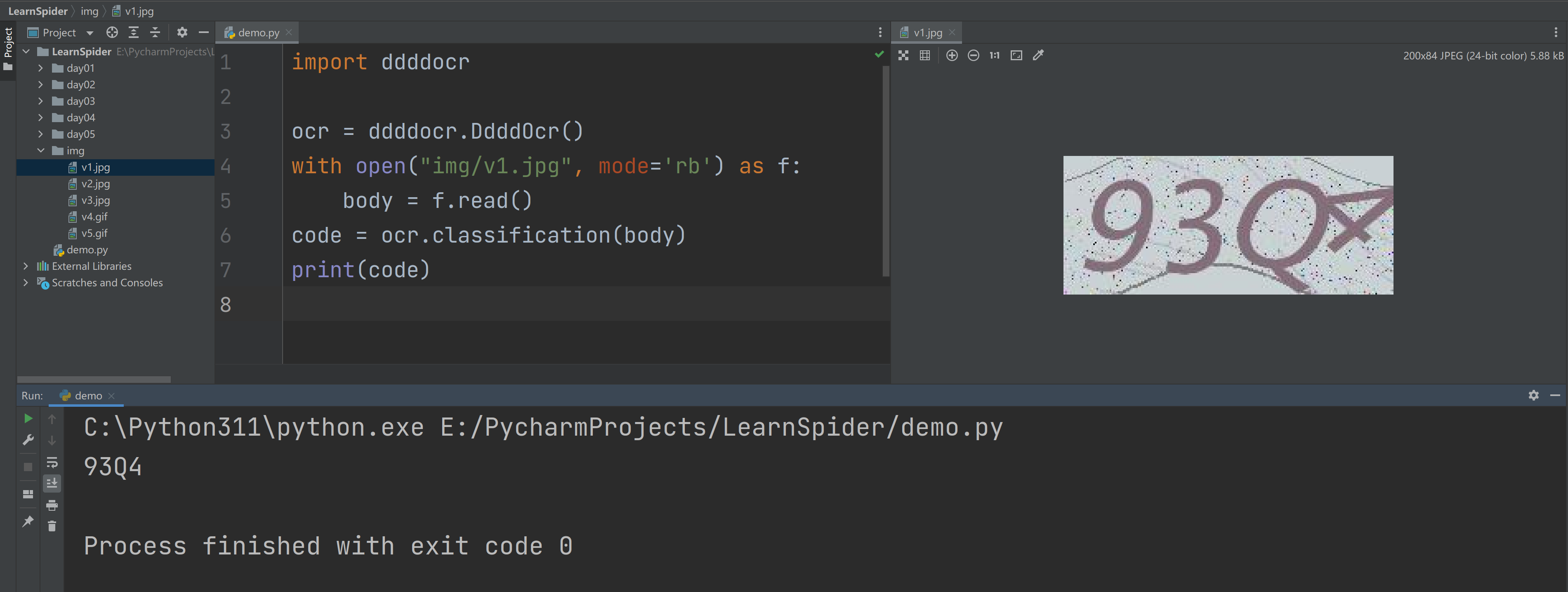
2.1 本地识别
1
2
3
4
5
6
7
| import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
with open("img/v1.jpg", mode='rb') as f:
body = f.read()
code = ocr.classification(body)
print(code)
|
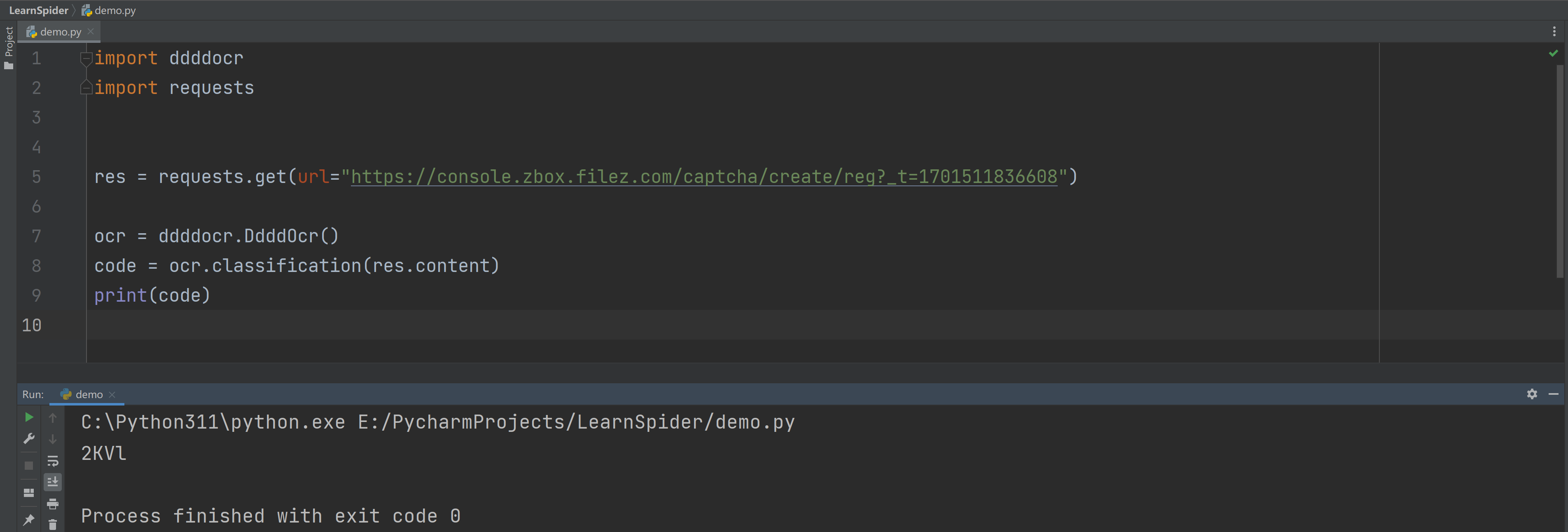
2.2 在线识别
也可以直接请求获取图片,然后直接识别:
1
2
3
4
5
6
7
8
| import ddddocr
import requests
res = requests.get(url="https://console.zbox.filez.com/captcha/create/reg?_t=1701511836608")
ocr = ddddocr.DdddOcr(show_ad=False)
code = ocr.classification(res.content)
print(code)
|
1
2
3
4
5
6
7
8
9
10
11
| import ddddocr
import requests
res = requests.get(
url=f"https://api.ruanwen.la/api/auth/captcha?captcha_token=n5A6VXIsMiI4MTKoco0VigkZbByJbDahhRHGNJmS"
)
ocr = ddddocr.DdddOcr(show_ad=False)
code = ocr.classification(res.content)
print(code)
|
2.3 base64
有些平台的图片是以base64编码形式存在,需要处理下在识别。
1
2
3
4
5
6
7
8
9
10
11
| import base64
import ddddocr
content = base64.b64decode("iVBORw0KGgoAAAANSUhEUgAAAGQAAAAoCAYAAAAIeF9DAAAHGElEQVR4Xu2a2VNTZxTAHZ/62of+BX3rdPrUmaq1da3WQWur1mqntrQWLe7UkUoQlEWFqFDZZN8hUBWKQUVpQDCyVUeltVWIIiAEZHWBAEk4zffZe+bmS+6SEEzE/GbOkHvPuXeY85t7vyWZBV48ilnsCS/uxSvEw3hthJydXWITnsiMFyLWfLGcu5jRQuQ2W27dy8ArBOTXvQxmrBBHm+xo/XQhKkTffRu0NSfgt8KvISttGaQlfQyFOWtBXboDbt7Ig6HBdvYSj6C7awDC3kqGg4oC8N0YC6uWhcPCOUHgszQMtvudgsK8Gnj2dNTqGmeErH47Z8rBYlfI6MgAXLqwH5Lj50iGJzL//UDJWP1pBDTfasNrnBEyHdgIef6sF1R5X9o0Xig8Ebb5QrF8QajlLTDoMTIIVkLMZiOcKfrWquGXLyqgo70BDKNDNG8wDFleCTehsS4JivK/4l/uMWxco4T4WDUo30yH+zo9PH0yavn/x+nnuBg1LPhgP0qJjjzjuUJuNGWiiJSEedByt4KffiWxt9bIz65GISveO2CVczcoxGQah+y05SikqT6ZX/fKw4khkfNGEQpZNDeILXUrKKT13mWUkZmyBIxGA7/O5XT2PoL0c9kQcPIX+D5yK2w/vgcis6Oh5qYWJicnac2msM0YrmRw4BkK+cwyA3OEuLh4CApS0GhoaGTTNtTXN2B9fHwCm7YBhdRWR6GQK5rD/BqXU9FQCb4RflYN50d0fgwYxsemTUjJ6ToUEh6iYtOi1NXVY4MTEhLZtA2khquvr69n0zagEP5gfu/uBXruga4aykr8ISv1E0g/tRBUueug+o8I6NH/hTdwFO3tOhsB9iK5NN2lQsbHjZbJSR9kplbC4nkKKsNnySHoejTAlooyOjoKisAXDSYRN2cvW4Lo9XqsCwkJpddKgUJyM3xQSH9fC9RUHbWabbFBnigy63KEEcMIbI3agU0mrynN9WoYfDoIJrOJ/iXH5DwryFnYqS4XP26Kg86OPrZcklPvBIBKVYSNVqvL6Tl7qNVqrCsqKmbTdkEhaUkfYbOv1cbaCLAXNVVR/HtJQl5VXIO3Ru+E3sHHbAmFnCf56RKyb3cmPLjfw5bKgjS/tVWHjY6IiISkd22FmEwmmuPqdDodW2IXFJKaOB8bnZr4IRQXbITWlst01U6ehJGRfnpM1h58KY68vo4VxGKD1doXr0UhSH66hHCx/+dsePJkhL1EkiSLlJDdQdjs5mbbHjQ3N2NeqTyGExUpUAgZJ7gmny32BeOE/ffdhOX8adUmrK2qlD9L2RWzFxvc3adn01Z09XW7RAiH0WiCx73DoKm8DVt8E1DK+tVRTknRaDTY8MzMLDZNz3F5jaaKTQuCQgpy1mCTH3U08Wts6LSs3Lnawty1bFoQMr3lGjxhnGDTVpC8K4XwMZvNELwvF6XEnTjHlkgyPDwMCkUwbTj5S47l5KRAIefL9mCThZ4ODpLnasnsSy6eIoTQ/vAxClm36iibloXQUyD19IiBQhquJTgnJHkRmxbEna8slgnLNJgT4uxq3d44QYJ8FhtfxEAhXZ3XscmdHeIrULLZyNWq8tazaUHcMagL0XKvC4WQ70ucwXYmdZ/OprhjkiM1joBCJifNkJe5kjaZDuoCWyfsoO7I1Ncd0157jI1NwC7/FBQSGJDFlsiGv9YoLi6m6w3uuLy8nC2XxGq395+/S7HRZNqra6m0rC4HLYOgif4lx8X5G7AmOX4uDPTLm18T7C0Mq65fsSwIh/5fGA7R46ksDDd8oYSTx89BnfZfut1O9q1MJjPdfm970EO3Tcj2PH/6e7XmDnsb2bCrcRLcsV7v+FrHSgh5SviDu1RUrAyB1tlX+beQRO7WSUppBn7+LtyPvY0g/EbLicOH5K2gxeDvV3GRmJjElsnCSgiBDNgV5wNtms8P8l3Jn41pluoXix0ixRExcjYXh58/weOflLvYWwjCNlwoyECennzJ8vTLW7CJQXZ9WSGNjeLjsBA2Qjja27RQeTEYcsJW0G2VjJTF9McO2toYwR83OCKFbL+nlWVBwK+BdDq87Zj19jvJc0ICE4PZywUhP3BQ/94E4QdU8MM3J+HzFZH0Bw5L5wfDGp8jsHdnBuRlVdNFoqswGAwQGnoQZZDPY2NjbJksBIUQHGkwhzPX2KPkShkKSTqbwqZnLIJCptLYqVxLaNd3gN/RbSik9paWLZmxuEVIcMohKL92EVo6dNA/PABGk5F+IdXW/RBOV5XA5iP+KMNfuRvGJ8bZW8xY3CKEHcTFouGO+L7aTMNjhWw+7P9avao4BIUQpBprDznXtPd0wJmqUjiSo4R98Qq6WPSN2EIXhBFZUXRAJ9Pe1xFRIQQ5DeZwpNaLfSSFEEijxZotlfciH1lCOLjGs+HFdTgkxMv08x9BPe61Ol73uQAAAABJRU5ErkJggg==")
ocr = ddddocr.DdddOcr(show_ad=False)
code = ocr.classification(content)
print(code)
|
3.案例:x文街
https://i.ruanwen.la/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import requests
import ddddocr
res = requests.post(url="https://api.ruanwen.la/api/auth/captcha/generate")
res_dict = res.json()
captcha_token = res_dict['data']['captcha_token']
captcha_url = res_dict['data']['src']
res = requests.get(captcha_url)
ocr = ddddocr.DdddOcr(show_ad=False)
code = ocr.classification(res.content)
print(code)
res = requests.post(
url="https://api.ruanwen.la/api/auth/authenticate",
json={
"mobile": "手机号",
"device": "pc",
"password": "密码",
"captcha_token": captcha_token,
"captcha": code,
"identity": "advertiser"
}
)
print(res.json())
|
4.练习
https://hrtechchina.com/register
http://user.shangwuwang.com/public/register
https://apeclass.com/